Who Reads Your Prompts
Data retention, training, and abuse review across AWS Bedrock, Azure, Vertex, OpenRouter, Anthropic, and OpenAI. Your Claude Code login picks the terms.

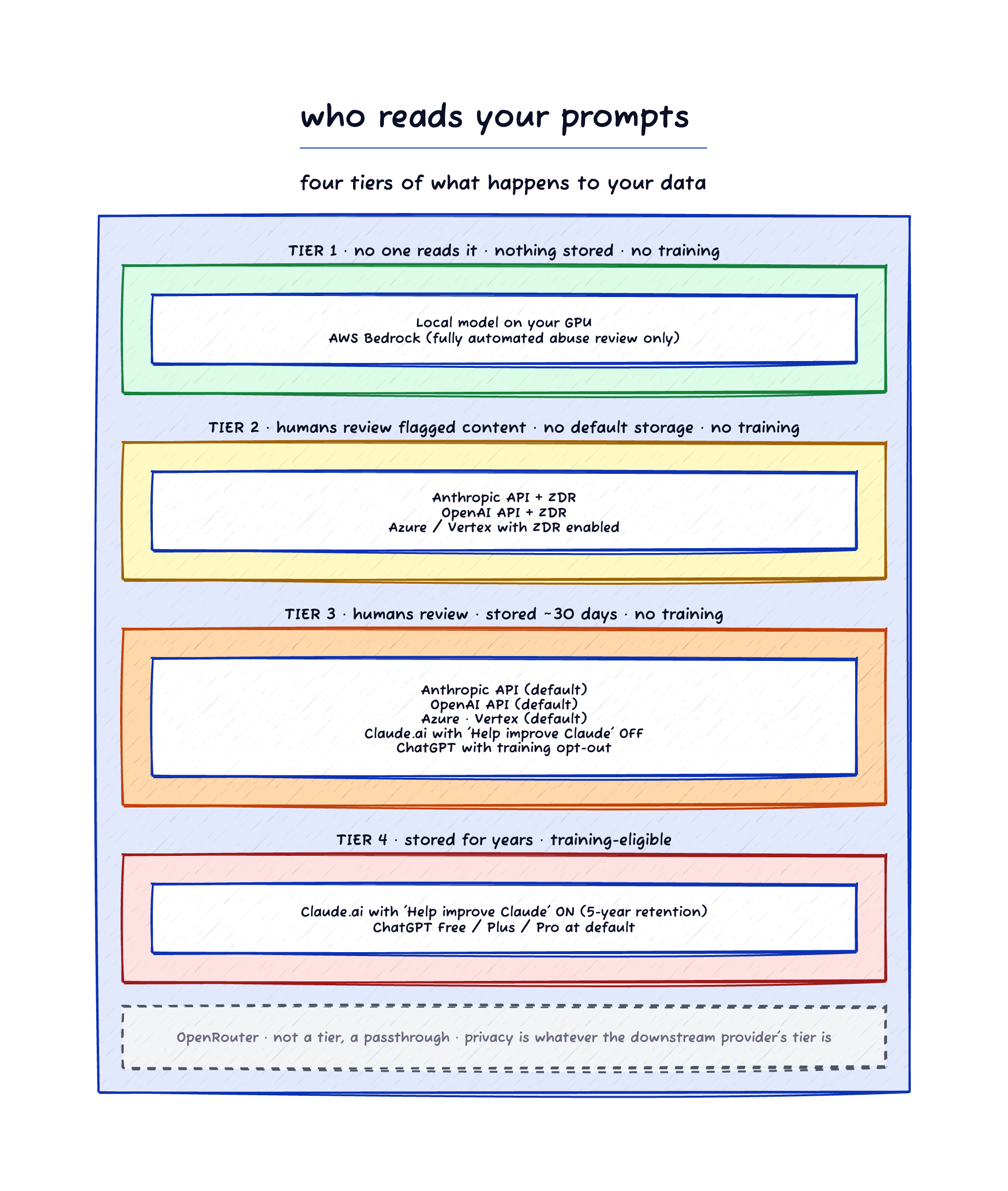
You are thinking about leaving Claude. Or supplementing it with a cheaper API — AWS Bedrock, Azure, Vertex, OpenRouter, OpenAI. The pricing math is straightforward, the model catalogs overlap, and every coding agent supports every backend. The dimension that gets less attention — and that may matter more once you have made the switch — is what each provider does with the prompts you send them. Six providers, three architectures, very different commitments.
Who Reads Your Prompts
Claude Code asked me, the other day, whether I was sure I wanted to push a commit to GitHub. The diff was three lines. I said yes.
Meanwhile I had “Help improve Claude” toggled on. So while the agent was being careful about my single commit to a private repository, every file it had read during the session — the journal entries, the .memory folder with personal notes, the resume in the career/ directory, the half-finished article drafts — was already on its way into Anthropic’s five-year training-retention window. The agent was guarding the exit. The front door was wide open by design.
The safety prompts encode a reasonable assumption: the provider is “us.” A leak is something that goes to a third party. GitHub is a third party. Anthropic is not. If your assumption is different, the model of where your prompts go has to start somewhere else.
If you are paying attention, you probably noticed that frontier models cost roughly the same per token whether you call them through Anthropic direct, AWS Bedrock, Microsoft Azure AI Foundry, Google Vertex AI, OpenRouter, or OpenAI’s platform API. The real savings come from switching to a smaller model — Sonnet instead of Opus, GPT-5.4-mini instead of GPT-5.5 — not from switching providers. The model catalog overlaps. Every coding agent worth running supports every backend.
So the comparison across providers is mostly settled, except for one thing you may not have looked at. What does each provider do with the prompts you send them?
In 2004, Google offered a gigabyte of free Gmail storage when the rest of the industry was capped at five megabytes. We took the offer. We made jokes about Google reading our email and then forgot the joke. A decade later the indexed corpus was part of how Google trained Smart Compose and the spam classifier and, eventually, the underlying language models. The lesson wasn’t don’t use Gmail. The lesson was know what you are handing over. That lesson applies here, with one big difference— this time you are paying for the service. The data trade is bundled with the bill. This is part of the same pricing shift I wrote about in The Squeeze. All you can use subscriptions are giving way to per-token billing, a customer relationship that looks more like a utility, while the data extraction continues underneath.
What’s actually in the prompt
An agent’s prompt is not just what you typed. It is a running transcript of every file the agent has read since the session started, every tool result it received, and every previous turn — sent back to the provider on every subsequent turn until the session ends.
Run the agent in your home directory and the prompt grows to include the README of whatever project is checked out, the resume that lives in your repo, the journal entries you keep in plain markdown, the kids’ ballet schedule and soccer roster you stored under Documents, the .env file the agent opened looking for configuration, the accumulated notes about you in a memory directory. The agent does not need to be malicious. It just reads files. Every file it reads ends up in the conversation history. Every conversation history ends up at the provider.
Use the same agent as a coach or a thinking partner and the conversation itself is the dataset. The notes about your job interview, the draft email to a recruiter, the half-formed thought about quitting — those are not metadata. They are the prompt.
PII leaks accidentally. The email address in your git config rides along with every commit context. Real names in test fixtures. The address on the resume. Phone numbers in a contacts file. The kids’ first names in a calendar file. None of these were prompts you wrote. All of them are prompts that got sent.
The retention policy you are about to compare across providers applies to all of it, not just the question you asked. And the next provider you switch to applies its own retention policy to all of it from that point forward — same files, new logs.
Three questions
Privacy is not a single dimension. You should think of it as three questions.
Do you want anyone to read it at all? Every hosted provider runs abuse monitoring — automated systems that scan prompts for content the provider’s policy prohibits. The policies vary slightly but the core list is the same: child sexual abuse material, weapons of mass destruction, large-scale fraud, malware development, election interference, sometimes copyright. When a prompt flags, the response is either fully automated (Bedrock) or escalated to a human reviewer who reads the prompt to make the call (Azure, Vertex, the frontier labs). The reviewer is a real person on a real laptop. If you answer is “no one”, that is only available with local inference, since every hosted provider has staff who can technically access logs under some scenario.
Do you want it stored? Storage means subpoena risk, breach risk, and internal-misuse risk regardless of whether anyone reads it. Zero Data Retention (ZDR) turns this off — your prompt is processed and the only artifact left is the response you received. Default retention windows widen the window of exposure: 30 days at most labs, 90 days for Vertex’s flagged content, two years for Anthropic’s flagged content, five years for opted-in Claude.ai consumer chats. The OpenAI court order in 2025 is the textbook reminder that “30 days” is a default, not a promise — a federal magistrate ordered preservation of every consumer chat and non-ZDR API call for four and a half months while the New York Times lawsuit was active. “Stored” means “stored as long as someone with authority says so.”
Do you want it to become training data? This is the only consequence that is forever. Once your prompt is in the training corpus, fragments may surface in model outputs to other users for years, and the corpus is not retractable. The developer APIs of every major lab (Anthropic, OpenAI, the hyperscalers) have committed to no training on customer content. The consumer chat products (Claude.ai, ChatGPT) have not — Claude.ai flipped to opt-in-by-default in August 2025; ChatGPT Free, Plus, and Pro train by default with the opt-out buried in settings.
Most personal users worry about question three first, and stop there. Security and legal teams worry about all three, in that order — because being read is the immediate exposure, being stored is the latent exposure, and being trained on is the permanent exposure. The recommendation that follows maps work to the question that matters most for it. But first, the providers themselves.
Three architectures
The six providers in this article split into three categories. The differences within each category are smaller than the differences between categories.
Hyperscaler enclave — AWS Bedrock, Azure AI Foundry, Google Vertex AI. The hyperscaler deep-copies the model lab’s weights into its own accounts. When you call Opus on Bedrock, Anthropic does not see your prompt. When you call GPT on Azure, OpenAI does not see it. You contract only with the hyperscaler [1][2][3]. This is the strongest privacy posture by default, and it is why hyperscalers became the path most enterprises took for AI.
Direct from the model lab — Anthropic API, OpenAI Platform API. The developer API is a separate product from the consumer chat (Claude.ai, ChatGPT). Same lab, same models, very different terms. The API does not train on customer inputs or outputs (since March 2023 for OpenAI, contractual under Anthropic’s Commercial Terms). Default abuse-monitoring retention is 30 days. Zero Data Retention is available on application [4][5]. The consumer chat products are governed by their own policies — covered later in this article — and are easy to confuse with the API because the company name on both is the same. Most coding agents default to the API when authenticated with an API key, including Claude Code.
Broker — OpenRouter. You contract with OpenRouter; OpenRouter decrypts your request and forwards it to whichever downstream provider you selected. The downstream provider sees the full prompt and is governed by its own terms. OpenRouter’s own terms disclaim responsibility for what the downstream provider does: “We do not control, and are not responsible for, LLMs’ handling of your Inputs or Outputs” [6]. OpenRouter offers configuration knobs — Zero Data Retention routing, training-eligible filtering, per-provider allow and deny lists — but the privacy story you get on OpenRouter is something you have to believe in, not something you contract for.
A fourth path sits alongside these three: open-weight models hosted on neutral infrastructure (Together, Fireworks, Groq, Cerebras) or run locally on your own GPU. The Chinese open-weight ecosystem is wider than most Western readers track:
DeepSeek V3 / R1 (DeepSeek). Strong coding performance at a fraction of frontier prices. The reason this category became unignorable in 2025.
Qwen 3 (Alibaba). A model family from sub-billion-parameter local-laptop sizes through frontier-scale, covering most of the cost/capability curve in one place.
Kimi K2 (Moonshot). Long-context option. The pick when the task is “read this entire codebase” rather than “answer this specific question.”
GLM-4 (Zhipu). The standard third pick when you want a non-DeepSeek, non-Qwen alternative for variety.
An open-weight model is software. The lab that trained it is not in the request path. When you call DeepSeek’s weights running on Together’s US infrastructure, your prompt goes to Together — not to DeepSeek. Together’s terms apply. PRC data law does not, because no PRC entity is processing your prompt. The same weights called against DeepSeek’s own Chinese-hosted endpoint reverse this completely: PRC data law applies, and government-access provisions no Western privacy review will sign off on come into the picture. Same model. Different jurisdictions. The choice of host is the privacy decision, not the choice of model.
Three lanes, not one
Given the four architectures and the three questions, the pattern security and legal teams converge on is not “pick the best provider.” It is “stop sending everything to the same provider.”
Three lanes, matched to three sensitivity classes:
Sensitive work. Private code, client material, financial planning, anything about your kids — the school they go to, the soccer roster, the ballet schedule, the medical appointments. Anything related to your job hunt. Anything in your journal, your therapy notes, or your half-formed thoughts about quitting. Anything you would not want pulled into a court discovery request, leaked from a breach, or surfaced years later in a model’s output to a stranger. Hyperscaler enclave (Bedrock, Azure, Vertex) if you have an account. The developer API with Zero Data Retention turned on if you do not. (The developer API is a different product from a Pro or Max subscription — same lab, different terms; covered below.) Not consumer subscriptions. Not Chinese-hosted endpoints. Not OpenRouter.
Everyday work. Open-source code, hobby projects, scratch experiments — work whose ceiling is “I would post this on GitHub anyway.” Developer API works fine. Local open-weight models work fine. Consumer subscriptions are tolerable here with training opt-outs flipped off, accepting that the toggle can change later.
Cheap experiments. Model comparison, benchmark runs, throwaway prompts that carry no real data. Open-weight models on Western neutral hosts (Together, Fireworks, Groq) or run locally — this is where the variety lives, and the prompts have no leak surface to defend. OpenRouter routes through its own decryption step before the downstream provider sees anything; the privacy story is whatever you assemble from configuration. Reasonable for benchmark runs, not somewhere to send work that has to stay private. The architecture puts a third party in the middle of every call, and that is the point of the service.
The mistake most personal users make is running every kind of work through a single coding agent pointed at a single provider. That collapses three decisions into one and forces every prompt — sensitive or not — into whichever lane the configured provider sits in. The fix is mechanical: separate sessions, separate authentication, different ANTHROPIC_BASE_URL values for different working directories.
The comparison
Three patterns stand out, as of April 2026.
First, the enclave providers are the strongest default privacy posture, but they are not identical. Bedrock is the strictest — fully automated abuse detection, no human review at all. Vertex has a unique 24-hour in-memory cache the others do not, and the longest abuse-flagged retention at 90 days. Azure sits in between, with the most opaque current documentation; the widely-cited “30 days for abuse monitoring” figure that everyone quotes for Azure no longer appears in the current data-privacy doc as of the October 2025 rewrite [2]. If you are picking among the enclaves on privacy alone, Bedrock has the cleanest story.
Second, the direct-from-lab providers sound roughly equivalent on the API but diverge on the consumer side. Anthropic flipped Claude.ai consumer chats to training-eligible by default in August 2025, with retention extended from 30 days to five years for users who toggle “Help improve Claude” on [7]. OpenAI’s consumer chats train by default — the opt-out is in Settings → Data Controls and is easy to miss. The API defaults are the opposite for both: no training, 30-day abuse retention, ZDR available. The trap is using a consumer subscription as if it were a developer tool.
Third, OpenRouter is a man in the middle of every call you make through it. That is not a flaw — it is the service. Your request is decrypted at OpenRouter’s servers, then re-sent to whichever downstream provider you selected, who is governed by its own terms. The defaults are reasonable (no storage by default, no routing to training-eligible providers unless you flip a toggle) but the privacy story you get on OpenRouter is the one you assemble from configuration, sitting on top of an architecture in which a third party is reading every prompt before forwarding it. Reasonable for benchmark runs and cheap experiments. Not reasonable for anything sensitive — even on a clean configuration, you are trusting two parties instead of one.
The Claude Code routing trap
If you use Claude Code, where your prompts go depends on how you logged in.
The same claude binary can route through six different privacy regimes. Authenticated with a Claude Pro or Max subscription via OAuth, Claude Code runs under consumer terms — the same terms as Claude.ai. If you ever toggled “Help improve Claude” to on, your coding sessions are training-eligible and retained for five years [7]. Authenticated with a Commercial API key from the Anthropic console, Claude Code runs under the Commercial Terms — no training on customer content, 30-day default retention. Set CLAUDE_CODE_USE_BEDROCK=1 and you are on AWS terms. Set CLAUDE_CODE_USE_VERTEX=1 and you are on Google’s. Set CLAUDE_CODE_USE_FOUNDRY=1 and you are on Microsoft’s. Point ANTHROPIC_BASE_URL at OpenRouter and you are on the broker’s terms, with whichever downstream provider OpenRouter routed you to also in the picture.
The trap is that Claude Code’s interface does not surface which regime applies. A developer paying $100 a month for Claude Max may assume their paid subscription comes with stronger privacy than the API. The opposite is true. Consumer terms apply to consumer subscriptions, including when those subscriptions authenticate Claude Code.
What you get without a contract
The biggest privacy decision a personal user makes is not which provider — it is whether to authenticate with a developer API key or a consumer subscription. Same lab, different products, different terms.
A consumer subscription (Claude Pro, Claude Max, ChatGPT Plus, ChatGPT Pro) is a chat product. Terms are clickwrap, the provider can change them with a 30-day email notice, and inputs may be used for training unless you explicitly opt out. Anthropic flipped this default to opt-in for new and resumed Claude.ai chats in August 2025; OpenAI’s consumer ChatGPT trains by default and the opt-out is buried in settings.
A developer API key is a different product on the same provider. No training on customer content. 30-day default retention. Zero Data Retention available on application. The line between consumer and developer terms is the API key, not the contract size — a single developer paying with a personal credit card gets stronger commitments than a paying consumer subscriber on the same provider. This is the largest free privacy lever a personal user has, and most coding agents authenticate the wrong way by default. Claude Code authenticated through Pro or Max OAuth runs under consumer terms; switching to API-key authentication is a one-line change that most users never make.
Companies on enterprise contracts get more on top of the API tier — signed Data Processing Agreements with named sub-processors, breach notification, audit rights, tenant-isolated infrastructure on the hyperscalers, custom data residency, indemnification beyond “as-is.” A personal user with an API key on a personal credit card already has most of what matters; the contract terms add legal recourse, not stronger data handling.
What has changed recently
Three things have moved in the last eighteen months that are worth knowing about before you decide where to send your prompts.
The Anthropic flip in August 2025: Claude.ai consumer chats became training-eligible by default. Existing users had until October 8 to opt in or out [7]. The change is prospective — old chats stay out of training — but new and resumed chats are subject to the new terms.
The OpenAI court order: in May 2025, a federal magistrate judge ordered OpenAI to preserve all consumer chat data, including “deleted” chats and Temporary Chats, plus API outputs from non-Zero-Data-Retention customers, in connection with the New York Times copyright lawsuit. The order ran for about four and a half months. OpenAI returned to the standard 30-day deletion window after September 26, 2025 [8]. Users in the European Economic Area, Switzerland, and the United Kingdom were excluded throughout. ChatGPT Enterprise and Edu users, and API customers on ZDR, were exempt. About 20 million of the preserved logs are now headed to plaintiffs in discovery, de-identified and under a protective order [9]. If you ran a coding agent through the OpenAI API without ZDR during that window, your prompts may be in that sample.
The pattern in both cases: stated retention policy is contingent. The 30 days that was promised becomes indefinite when a court asks otherwise. The opt-out that exists today may not exist tomorrow. This is not unique to AI providers — it is how data-handling commitments work everywhere — but it is worth understanding before you decide what to send.
The smallest change worth making
If you read this far and do nothing else, the highest-leverage move is switching the coding agent you already use from a consumer-subscription login to a developer API key. Same model, same software, different terms — no training on your content, 30-day default retention, ZDR on application. Everything else in this article (enclaves, lanes, jurisdictions, open-weight hosts) is downstream of that one switch.
After that, the lanes. Sensitive work — kids, medical, legal, employer code, journal — belongs on a hyperscaler enclave or a developer API with ZDR turned on. Everyday code can stay on the direct API. Throwaway experiments belong on open-weight models hosted somewhere neutral, or run locally. The configuration cost of separating them is a one-time hour. The cost of not separating them shows up years later, in someone else’s logs.
REFERENCES
[1] AWS (2026). Data protection in Amazon Bedrock. https://docs.aws.amazon.com/bedrock/latest/userguide/data-protection.html
[2] Microsoft (2026). Data, privacy, and security for Azure OpenAI Service in Microsoft Foundry. https://learn.microsoft.com/en-us/azure/ai-foundry/responsible-ai/openai/data-privacy
[3] Google Cloud (2026). Generative AI on Vertex AI: data governance. https://cloud.google.com/vertex-ai/generative-ai/docs/data-governance
[4] Anthropic (2026). API and data retention. https://platform.claude.com/docs/en/build-with-claude/api-and-data-retention
[5] OpenAI (2026). How OpenAI handles your data. https://developers.openai.com/api/docs/guides/your-data
[6] OpenRouter (2026). Privacy: data collection. https://openrouter.ai/docs/guides/privacy/data-collection
[7] Anthropic (2025). Updates to our consumer terms and privacy policy. https://www.anthropic.com/news/updates-to-our-consumer-terms
[8] OpenAI (2025). Response to NYT data demands. https://openai.com/index/response-to-nyt-data-demands/
[9] Bloomberg Law (2026). OpenAI must turn over 20 million ChatGPT logs, judge affirms. https://news.bloomberglaw.com/ip-law/openai-must-turn-over-20-million-chatgpt-logs-judge-affirms