What Five Coding Agents Taught Me About Building My Own
Six coding agents, six teams, four languages. They all converge on the same architecture — and most of it may be unnecessary.

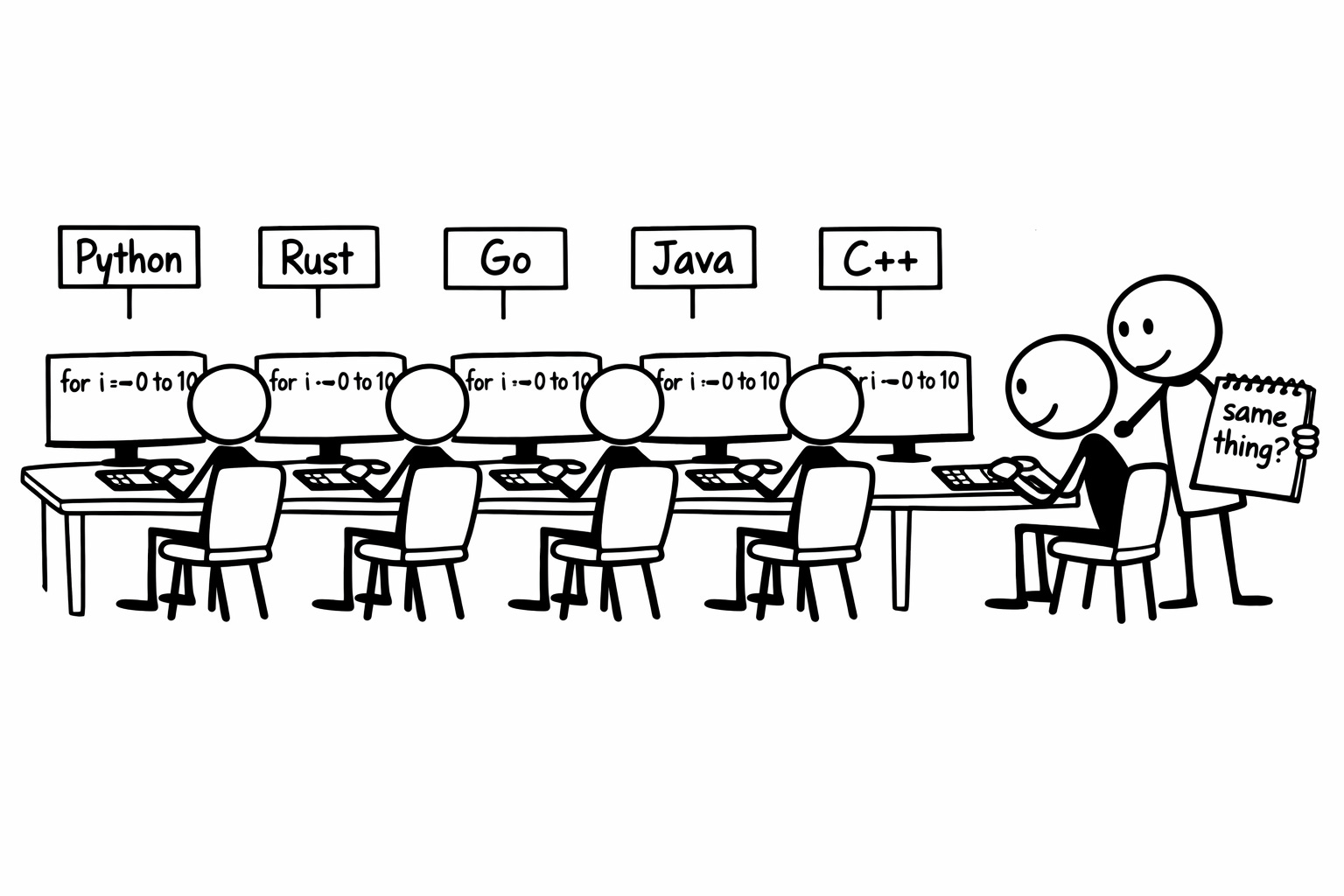
I analyzed the source code of five open-source coding agents — and the published analyses of a sixth, after Anthropic accidentally leaked it — before building my own. Here is what I concluded: the agents are overengineered for the problem they solve, most of the complexity exists because they are chatbots when they don’t need to be, and a simpler approach — let the model try, check if it compiled, git reset if it didn’t — may be all a coding agent actually needs.
Why Build Another One
I am building Press, a coding agent runtime library and CLI. A reasonable question: why build one when Claude Code, Goose, Aider, and a dozen others already exist?
Three reasons. First, Claude Code was built by a UX developer in TypeScript — this is not rocket science, and owning the runtime means understanding exactly what it does. Second, owning the runtime gives me the ability to instrument performance, add my own orchestration algorithms, and experiment with approaches the commercial agents don’t offer. Third, I am still looking for the cheapest way to use these models. When you control the runtime, you control which model gets called for which task, how many tokens you burn on context, and whether a $0.01 operation gets routed to a $0.10 model. The commercial agents don’t optimize for my budget. Mine does.
I have been using Claude Code in a restricted mode — scoped to a single directory, generating code from specifications, no elaborate conversation. It works. Most of the features Claude Code provides go unused. The permission prompts, the memory system, the context compaction — I don’t need them because the task is small, the scope is clear, and git is right there. I size the task to fit the tool. That daily experience is why I am now replacing Claude Code with Press — the features I don’t use are not free. They add complexity, cost tokens, and make the runtime harder to reason about. If I only need ten percent of what Claude Code offers, I should build the ten percent.
Before designing Press, I needed to understand what already existed. Not the marketing — the actual code.
What LLMs Get Wrong
Some parts of a coding agent are obvious. The loop is obvious: read context, call the model, parse the response, execute tools, repeat. Letting the agent call tools is obvious — every model provider has a tool-use API. What is not obvious is what to do when the LLM returns something the software can’t use.
I have been building ML systems for over a decade. In traditional ML, the model can be wrong — it can return the wrong label or the wrong number — but it cannot return something that isn’t a label or a number. The output space is constrained. The software knows the format. It only has to worry about whether the answer is correct.
LLMs make two kinds of mistakes, not one. The first is familiar: wrong answer, right format. The model edits the wrong line, or writes a function that doesn’t handle an edge case. You detect this with compilation, tests, linting, review. The second is new: answer in wrong format. The model returns a diff that isn’t valid syntax. It returns a tool call with missing parameters. It produces a search/replace block where the search string doesn’t match anything in the file.
Traditional ML doesn’t make the second mistake. LLMs make it constantly. That is the integration problem — and it is what I went looking for in the source code.
What I Found
I analyzed five open-source agents — Aider (Python), Goose (Rust), SWE-agent (Python), OpenHands (Python), and OpenCode (Go). In late March 2026, Anthropic accidentally shipped an unminified source map inside a Claude Code npm update, and multiple independent analyses of the sixth agent followed [1] [2]. I am not going to pretend I didn’t read them.
Six agents, six teams, four languages. Under the hood, three patterns.
No agent shows the model all its tools at once. Every agent filters the tool list before each API call. Give the model too many tools and it hallucinates tool calls, picks the wrong tool, or invents combinations the runtime can’t execute. Give it too few and it can’t do its job. Every agent makes this trade-off differently.
Every agent has to map the model’s text output to structured tool calls, and the mapping fails regularly. Missing parameters. Wrong types. Tool names that don’t exist. Every agent builds a parsing layer between the model’s output and the tool dispatch, and every agent builds retry logic around it. The strict approaches fail more often but fail cleanly. The lenient approaches fail less often but fail in ways that are harder to detect.
Every agent has a different way of applying file edits, and most of them are more complicated than they need to be. The agents use at least four strategies: exact search-and-replace, unified diffs, whole-file replacement, and hybrids that try multiple formats. The simplest approach is exact search and replace: the model provides the old text and the new text, the runtime finds the exact match and swaps it. If it doesn’t match, the edit fails. Everything more complicated than that is putting lipstick on a pig. If the model can’t produce an exact string match for the text it wants to replace, the model doesn’t understand the file well enough to edit it. Falling back to fuzzy matching hides that failure instead of surfacing it. The strict approach loses more edits. It loses fewer files.
In every agent, the runtime controls the loop — not the model. The marketing says “the AI writes your code.” The source code says the runtime decides which tools the model can see, how the output is parsed, whether an edit gets applied, and what happens when something fails. Raschka’s analysis of Claude Code concluded that the perceived capability gap between it and plain chat “stems largely from harness design rather than underlying model differences” [1]. Claude Code is not magic. It is the same architecture as the open-source agents, with more polish and a larger engineering budget.
The convergence across all six agents is real, but it tells you more about where the models are weak than where the designers are smart. If the next generation of models fixes these limitations — reliable structured output, consistent edit formatting — the architectures would look different.
What a Coding Agent Actually Needs
Every line of code you don’t write is a line that can’t have a bug in it. So the question is: what is the bare minimum?
A few tools. Read a file. Write a file. Run a command. Search. Maybe five more. That’s it. You don’t need forty tools. You don’t need dynamic tool discovery. You don’t need MCP (Model Context Protocol) servers or LSP (Language Server Protocol) integration. Those are nice to have. They are not the minimum.
Git. The filesystem is under version control. A bad tool call is not a catastrophe — it’s a bad commit. You revert it and try again.
A zero-trust execution environment. The agent runs as a restricted user with group membership that whitelists only the directories it needs. Ordinary Unix file permissions — the same mechanism you’d use to restrict any process. The agent physically cannot touch anything outside the project. You don’t need application-layer permission systems when the OS already enforces boundaries. Put it in a container, a VM, a restricted user account. That’s not agent engineering — that’s ops.
Exact search and replace for edits. The model provides the old text and the new text. The runtime finds the exact match and swaps it, or fails. No fuzzy matching. No alternative formats. If it doesn’t match, the model tries again.
Deterministic orchestration for everything repeatable. The agent does not operate git. The agent does not manage its own history. The agent does not decide when to commit or when to retry. Those are repeatable operations that happen the same way every time — so you write them as ordinary automation. Scripts. Compiled code. The orchestrator handles versioning, branching, committing, resetting. The LLM handles the one thing that is not repeatable: generating code from a specification.
This is a corollary of what Rich Sutton called the bitter lesson [3]: as training data increases, ML learns to do things better than human heuristics. But the flip side is just as important. If an operation is repeatable and always performed the same way, why would you want an LLM to do it? The LLM adds non-determinism to a deterministic task. Write the automation yourself. Reserve the model for the work that actually requires judgment.
A compilation and test check. Did it compile? Did the tests pass? If yes, the orchestrator commits. If no, the orchestrator resets and retries. If it can’t get it right after a few tries, no amount of governance was going to save you.
That is the minimum. Everything else — memory management, context compaction, session persistence, permission inspectors, hook systems, subagent orchestration — is engineering for the chat interaction. If you are generating code from a specification rather than having a conversation, you don’t need most of it.
Where the Complexity Belongs
The individual agent should be simple. The orchestration layer is where the real work lives.
The orchestrator decomposes the specification into tasks. It assigns each task to an agent instance running as a sandboxed user in its own worktree. It checks the output — compile, test, commit or reset. It tracks which tasks succeeded and which need retry. The individual agent needs three tools and a model. The LLM does one thing: translate specification text into code. The orchestrator is a tool that lets a human apply judgment — task size, parallelization, decomposition, when to give up.
This is how I write code myself. I have made every mistake possible over twenty years — deleted the wrong file, pushed to the wrong branch, deployed the wrong build. I didn’t respond by building a system to prevent mistakes. I built a system that catches them: version control, backups, staging environments, code review. The discipline is not about never making a mistake. It is about what you do when you make one. I don’t see why agents should be treated differently.
Do you even need a chatbot if you are just generating code? All six agents are built around a conversation. Memory management, context compaction, session persistence — all of it exists to sustain that conversation over time. But specification-driven development has no conversation. The spec is the context. Each task fits in a single prompt. The code is disposable. I have some evidence that this works — 320,000 lines of Go generated across 46 runs, differentially tested against GNU coreutils, most of it deleted and regenerated at higher quality each time.
Nobody at a frontier lab is publishing papers about this. I don’t work at a frontier lab. I’m just a guy with a MAX subscription and a 58,000-line orchestrator in Go that calls Claude in a loop. But the results are sitting in a public GitHub repo, and the approach sidesteps most of the problems that all six agents spend their engineering budgets solving.
What I’m Testing with Press
I could be wrong about all of this. I haven’t built Press yet — these are hypotheses, not results. Four of them:
Git is the safety net, not the agent. If the model does something wrong, revert and retry. Don’t build elaborate prevention when you have cheap recovery.
The OS handles security, not the agent. Sandbox the environment. Don’t reimplement file permissions in application code.
Small, focused agents beat general-purpose ones. A three-tool agent that does one job doesn’t need the governance infrastructure of a forty-tool agent that does everything.
Retry beats prevention. Let the model try. Check if it compiled. If it didn’t, try again. The models are getting better. The governance is not.
The six agents I studied were built by teams that have been running them far longer than I have. Their elaborate integration layers may exist because they tried the simple approach first and it failed. I’ll find out when I build the simple version.
The playing field between open-source and proprietary agents didn’t level because someone decided to be generous. It leveled because Anthropic made a packaging error. And the architecture that leaked looks the same as the architecture that was already public. That either means everyone independently arrived at the right answer, or everyone is building the same workarounds for the same model limitations and nobody has stepped back to ask whether the workarounds are the point — or whether the interaction model that demands them is.
REFERENCES
[1] Raschka, S. (2026). “Components of A Coding Agent.” Ahead of AI.

[2] Engineer’s Codex (2026). “Diving into Claude Code’s Source Code Leak.”

[3] Sutton, R. (2019). “The Bitter Lesson.” http://www.incompleteideas.net/IncIdeas/BitterLesson.html
[4] Djukic, P. (2026). “Dude, Where’s My Code?” Mesh Intelligence. https://meshintelligence.substack.com/p/dude-wheres-my-code
[5] Aider. https://github.com/Aider-AI/aider
[6] Goose. https://github.com/block/goose
[7] SWE-agent. https://github.com/SWE-agent/SWE-agent
[8] OpenHands. https://github.com/All-Hands-AI/OpenHands
[9] OpenCode. https://github.com/opencode-ai/opencode